Your best edge case fix is already sitting in a closed Jira ticket.
I know because I see it happen constantly. Teams spend hours in risk workshops predicting what could go wrong. They map scenarios. They argue about probability. They build elaborate risk registers. The energy is real. The output looks thorough. And almost none of it surfaces the edge case that will actually ship to production next quarter.
Here's what I keep noticing: the teams that finally break this cycle aren't the ones with better risk analysis. They're the ones that stopped predicting and started looking backward.
The Pattern Nobody Connects Across Teams

There's an uncomfortable truth hiding in most engineering organizations.
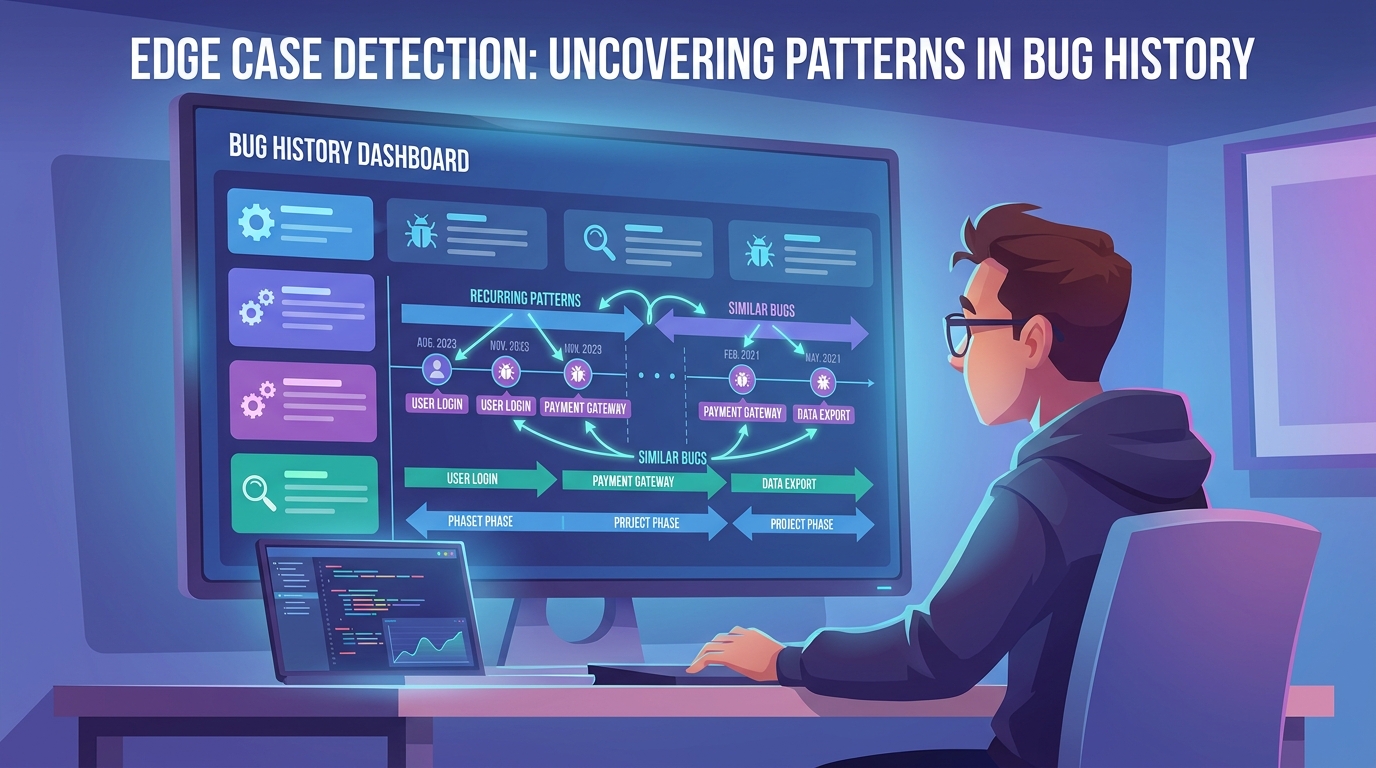
When a bug gets fixed, it gets fixed once. The ticket gets closed. Someone moves to the next thing. The knowledge is technically preserved in the Jira archive, but it's psychologically finished. No mechanism exists to say "this failure mode has unresolved cousins in three other features."
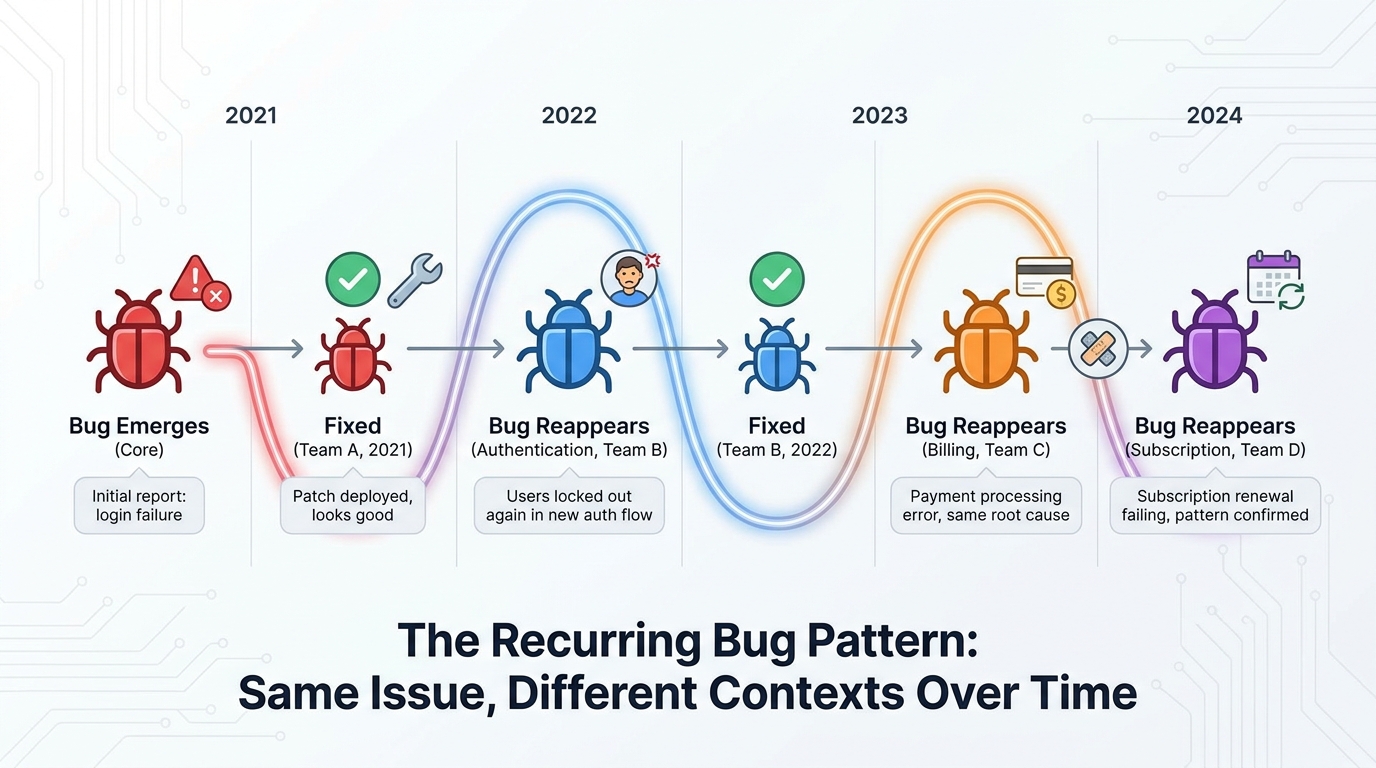
The same authentication timeout that a team solved last quarter appears again this quarter in a different module. A permission logic flaw that burned engineering hours in sprint six reappears in sprint 18 wearing a different feature name. The edge case that caused a production incident in the payment system manifests again in the billing system, then again in the subscription renewal flow. Not because the team is careless. Because the pattern was never indexed.
Research on open-source codebases shows that up to 45% of production bugs are defects that were previously fixed. The same bug travels silently through reused code, appearing in different features because nobody connected the dots. And here's the economic angle that makes it worse: IBM's Systems Sciences Institute documented that a bug fixed in production costs 100 times more than the same bug caught at the design phase.
Meaning: your team paid to fix this edge case once. If you re-encounter it in production, you're paying 100x that price the second time around.
Why the Obvious Fix Doesn't Work
The instinct is to run better risk workshops. Hire better analysts. Build more sophisticated foresight frameworks. Spend more time in pre-mortems.
None of it solves the fundamental problem.
Forward-looking risk analysis has an inherent ceiling. Daniel Kahneman and Amos Tversky's research on the planning fallacy shows why: when teams imagine future failure modes, they draw on an "inside view," a mental model of how this specific feature, in this specific context, could go wrong. This view is systematically optimistic because the human brain underweights base rates and overweights uniqueness. You cannot predict an edge case you have not encountered. You can, however, detect the same class of edge case appearing in four different features across eight quarters if you index what already happened.
That's not a prediction problem. That's a retrieval problem.
The Real Framework: Backward-Looking Pattern Detection
Here's the shift: stop asking "what could go wrong?" and start asking "what already went wrong?"
This isn't just better practice. It's a fundamentally different epistemology. Forward-looking analysis is bounded by imagination. Backward-looking pattern detection is bounded only by how much history you have indexed.
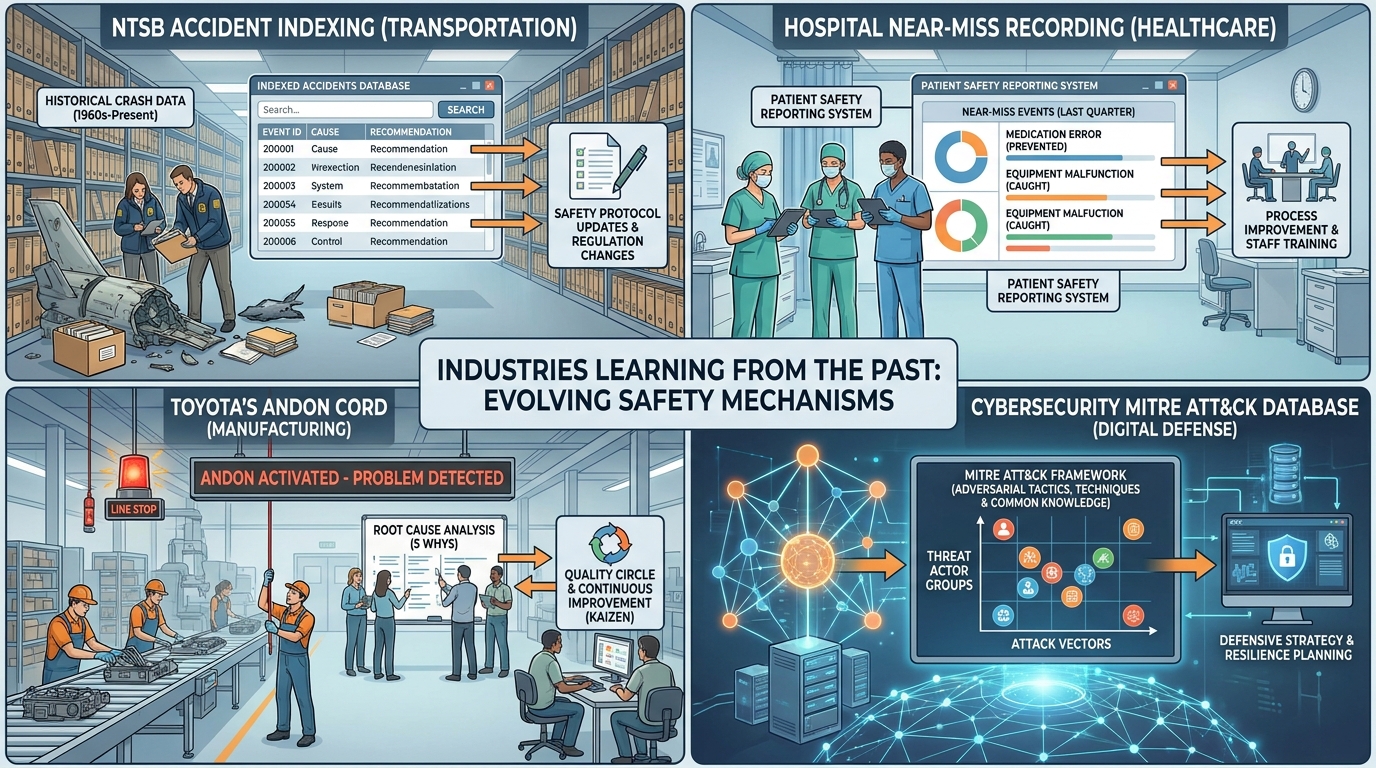
The NTSB understood this in 1962 when they built CAROL, a searchable database of every civil aviation accident investigated since then. When investigators encounter a new crash, they do not speculate about what might have caused it. They query CAROL for every prior accident with a similar event signature, flight profile, or contributing factor. The database makes pattern detection structural, not optional.
A production bug that recurs is not a new problem. It is a signal that the pattern was never properly indexed.
Medicine followed the same path. Hospitals that implemented structured near-miss reporting systems saw measurable reductions in adverse events. Why? Because research shows that near misses contain the same root causes as full adverse events. The only difference is luck. A surgeon's mistake that was caught at the last second carries the same signal as a mistake that made it to the patient. Both indicate a systemic failure waiting to recur.
Toyota's manufacturing principle of Jidoka operates on this exact logic. When a worker spots a defect, they pull the Andon cord. The line stops. The defect is logged. But here's the critical piece: the finding is distributed to every station, not just the one where it was found. A defect at Station 7 is a signal that Station 12 might encounter it in the next model if nobody makes the connection.
Every mature safety-critical domain arrived at the same conclusion: history is more comprehensive than imagination.
The $100,000 Question: Why Closed Tickets Become Orphaned
So if the data exists in your Jira history, why does the pattern keep repeating?
Two forces are at work. First, developer turnover. When a senior engineer leaves, every edge case they personally remember leaves with them. The closed ticket may exist in the archive, but nobody on the current team was there when it was written. New hires cannot know what to look for if they do not know what to search for.
Second, and more importantly, closed tickets are orphaned by default in knowledge systems. Once a bug is marked resolved, it exits the working memory entirely. There is no structural incentive to retrieve it. No question-and-answer system connects it to future features. It is preserved in form but destroyed in function.
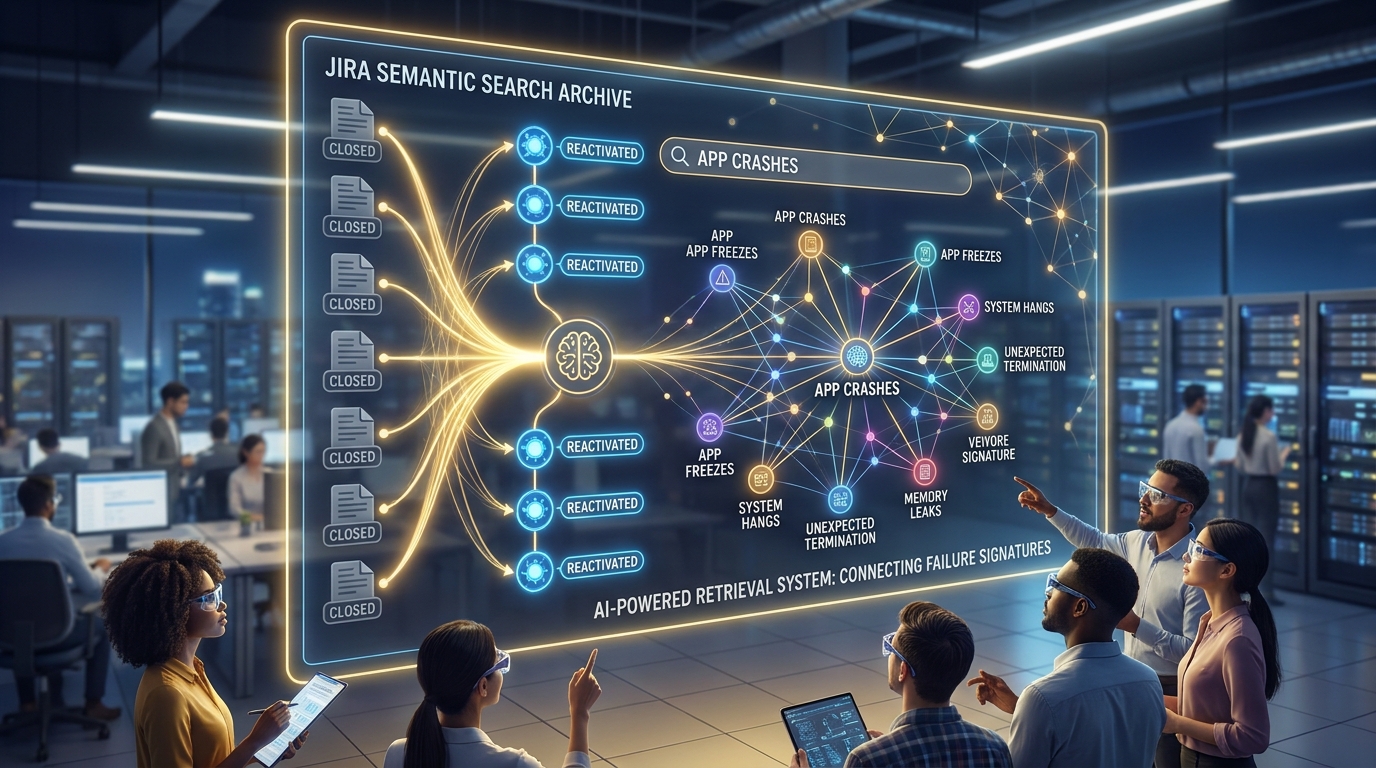
This is where traditional Jira search fails spectacularly. Keyword-based search demands that you already know the pattern you are looking for. A ticket titled "authentication timeout on slow connections" will not surface when a developer searches for "login failure on mobile networks," even though they describe the same failure class.
This is what vector embeddings and retrieval-augmented generation (RAG) solve. Instead of keyword matching, semantic search understands that "app crashes" and "app freezes" belong to the same failure signature. The same edge case appearing under different names becomes detectable. Closed tickets transform from orphaned records into actively queryable pattern intelligence.
Real Examples: The Patterns Teams Miss
A PM at a fintech platform discovered that their billing module had encountered and fixed the same race condition three times over 18 months. Different developers. Different PRs. Same underlying bug. The first time, it took engineering three days to diagnose and fix. The third time, it took six days because nobody thought to search the archives for prior occurrences.
Another team, a B2B SaaS company, found that a permission logic flaw they encountered in Q2 appeared again in Q4 under a completely different feature name. Same failure signature. Same economic cost. Only detected after shipping to production the second time.
These are not anomalies. The research on technical debt productivity loss shows that developers spend 30 to 50% of their working time on unplanned rework. Much of that rework is re-paying debts already closed in Jira.
Building the Index That History Needs
This is why we built Prodini's architecture around indexing, not generation.
When you write a spec, the system queries every bug ever filed against similar functionality. Not through keyword search, but through semantic understanding of what the bug describes. You surface the edge cases your team already paid to fix. The knowledge that was preserved but inert becomes actionable.
The risk workshop does not disappear. But it becomes reference-class forecasting instead of imaginative speculation. You are not inventing edge cases. You are detecting recurrences.
The Shift Happens Here
The teams breaking out of the pattern-repeat cycle made the same move: they stopped trying to imagine edge cases and started indexing historical ones.
Your organization has already solved the edge case you are about to miss. The knowledge exists. It just lacks the retrieval layer that aviation, medicine, and cybersecurity built years ago.
The gap between generic risk analysis and useful risk analysis is no longer a prediction problem. It is an indexing problem.
Try prodini.ai in beta to see how connected historical context changes specification.